
Most of my work as a trainer and analyst involves helping people learn about IT infrastructure. I like to use a storytelling teaching method based on real-world, hands-on deployment considerations. The problem is that real-world environments aren’t usually amenable to hands-on teaching. I have built a few demos and demo environments to support the storytelling. I think it’s time to tell the story of these storytelling tools, starting with the one I’m working on this month.
Granite
I built Granite to generate a workload that looks like users are accessing a business application I can run in a vSphere lab. I wanted all resource types exercised: CPU, network and storage. Multiple VMs working together is vital to generating these loads. I also wanted scalability to use the same framework to load my small lab at home and a larger environment such as the CTO Advisor hybrid cloud. Rapid deployment and re-deployment are important parts of a lab tool, so Granite needed automated deployment and central control. The efficiency of the actual code is not important; inefficient code that generates excessive load is more useful here than highly optimised code! This is a big difference between Granite and benchmarking tools, where performance is key, and production, where efficiency is vital. Granite is a data centre infrastructure noise generator!
Granite Application
The application mimics an order-taking and fulfilment system centred around a relational database. Granite has three areas: the Database, Web interface, and Workers.
The database is MySQL, which is the source of truth for the application and controls the workers. There are tables for products, customers, orders, and every stock item required to produce the products and a recipe for making each product from the stock items. One table controls the automation, enabling or disabling each task type and setting the wait time for each worker before running the task again.
The web interface is primarily for managing and monitoring Granite. The main page summarizes the current activity and allows control of the automation by updating the database table. By disabling the order creation task, I can allow the remaining tasks to be processed until all the orders are complete. I plan to add a manual order entry page to make it look like a real application.
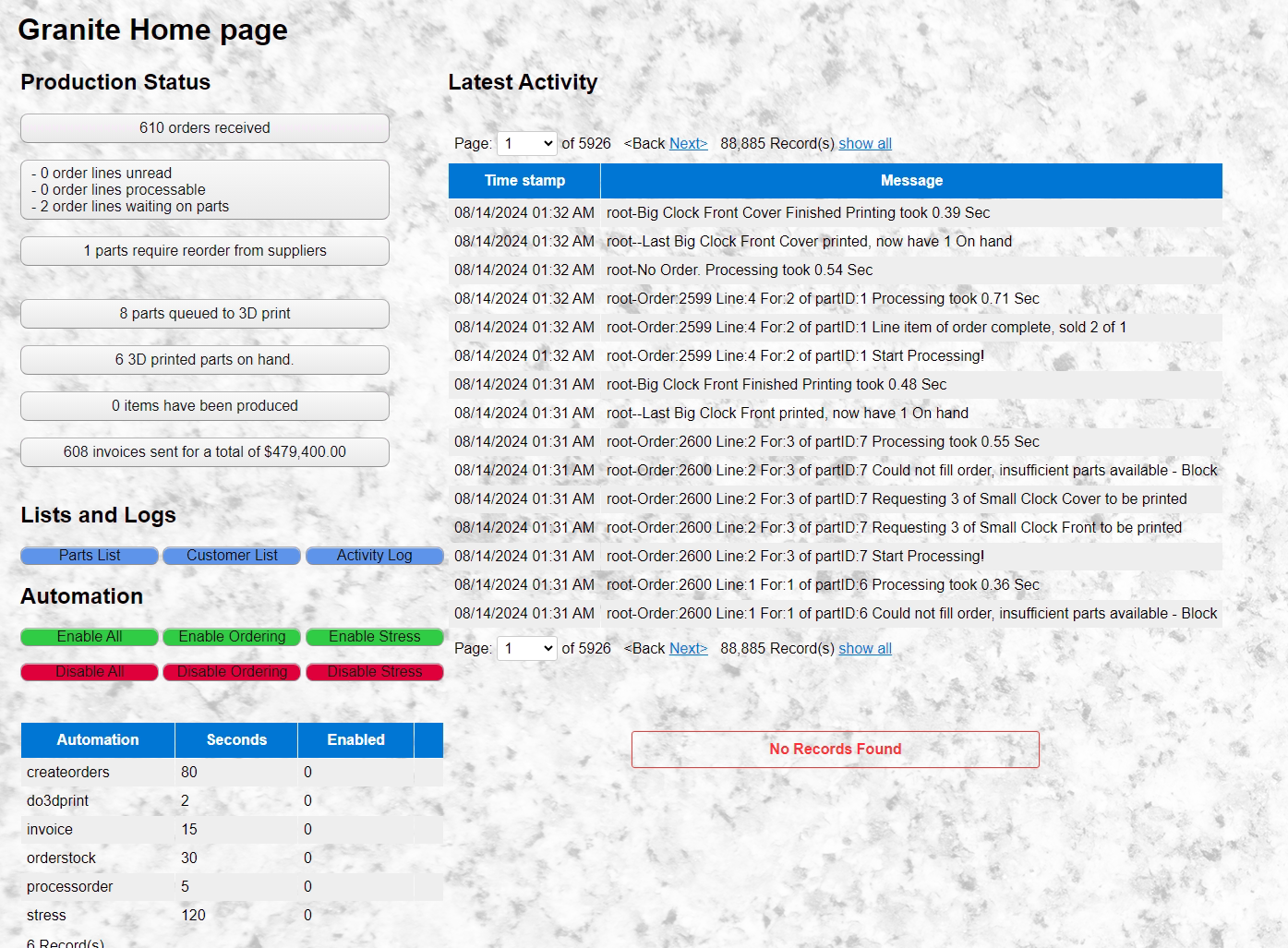
The workers run the tasks that make up the workflow, accessing the database to identify which tasks to run. The worker tasks are a series of Python scripts, one script for each action. A scheduler script launches these task scripts, regularly reading the database to identify how frequently to run each task. All tasks log status information into the database—again, less efficient and noisier is useful!
Currently, there are five task scripts:
- One task creates orders. Selecting a random customer who orders a random quantity of random products. The order is added to the database as new. The creation of an order triggers all the other tasks that follow.
- The next task processes active orders, randomly selecting one from the database. For a new order, it identifies the 3D-printed components required to produce, adds them to the production queue, and then marks the order open. For an open order, it checks whether the 3D-printed parts are on hand. Then checks whether components need to be ordered from external suppliers, and marks any required for re-order. If all parts are on hand, the order is completed by reducing the on-hand component count for each and marking the order complete.
- There is a task for 3D printing parts. It randomly chooses a part requiring printing, decrements the number queued to print, and increments the number on hand. I wish real-world 3D printing were so effortless.
- Another task orders parts from external suppliers. Parts are ordered in fixed quantities, and the database is updated to show that more parts are on hand.
- The final task is invoicing of completed orders. This task looks for completed orders and marks them as invoiced. The invoicing task also generates a PDF document of the invoice and makes it available to the web interface.
Initial implementation
Deployment in my vSphere lab uses a VMware template and an Ansible playbook. Other playbooks handle pushing code updates to VMs and resetting the database.
The initial build of Granite used eight VMs:
- Database
- Two web servers
- A load balancer for the web servers
- Three workers
- One invoice worker
This scale was enough to show my poor Python programming. Unintended re-processing orders meant I had a huge excess inventory of components after all the orders had been processed. I learned about database locking to avoid having two workers process an order simultaneously. The excess inventory wasn’t a problem; it was only a database table. However, making the application behave more production-like is important, and I want to be a less bad programmer over time.
CTOA Datacenter
Moving from my single-host vSphere environment to the CTO Advisor hybrid cloud gave me far more resources to play with. I scaled the workers to six VMs and processed a million dollars of orders in a day.
We had a project with Google Cloud that required the whole Granite application to be encapsulated in a single VM, so the Obsidian application was born. It uses the same code, running everything directly on a single VM with no containers but multiple scheduler scripts in parallel. The project looked at Google’s migration tools and moving the Obsidian VM from on-premises to Google VMs, then a single container on Google Kubernetes Engine.
Automation on Automation
The Ansible playbooks are great for deploying and redeploying Granite, but I also wanted to automate deploying the eight or more VMs. At the same time, Ansible Tower has been on my to-learn list for a while. I spent a few weeks learning to deploy and use AWX, the open-source version of Tower, to deploy VMs and then deploy Granite into these VMs. I might also write about that experience, as it wasn’t a straightforward process. I would be very interested to see how much easier the licensed version of Tower makes the process.
Current Project
The next project is to make Granite cloud-friendly, moving from VMs to containers and maybe functions. We will shift from dedicated VM resources that are idle when no task is running to on-demand resources where we aren’t paying for idle resources. In the next post, I will look at this process. Putting the individual worker scripts in containers and using Kubernetes as the deployment platform. Hopefully, we will also use Kubernetes as the scheduler.
© 2024, Alastair. All rights reserved.

 RSS - Posts
RSS - Posts