
The VI3 Install & Config course has a slide which talks about setting up the Service Console networking for HA. The key design item is to ensure that the SC network is fault tolerant but is still a representation of the health of the VM network.
The HA cluster is designed to start up VMs that were running on an ESX server in the cluster if that server has failed catastrophically. If the ESX server crashes then HA does a great job of powering on those VMs (let’s not get into the survivability of the guest OS on random power cycling, that’s dependent upon your guest OS). The place where we need to get concerned is where there is a partial network failure.
HA does it’s job by monitoring network communications between the Service Console on each ESX server in the cluster. If an ESX server can talk to some nodes in the cluster but not others then after 12 seconds of lost communication each ESX server attempts to ping an IP address, by default the default gateway for the SC. If this IP address is pingable by an ESX server then this server is part of the survivors of the cluster and the ESX servers that are uncontactable is failed. If this IP address is not pingable then this server is isolated from the cluster and should do what it can to allow the surviving nodes to power on the VMs it is running.
Consequently the SC networking is mission critical to VMware HA. If the SC networking fails then HA believes that there is a fault in the cluster. So HA is implicitly monitoring network connectivity as well as SC “upness”.
Consider the simple setup below, VM network separated from SC network with separate vSwitches:
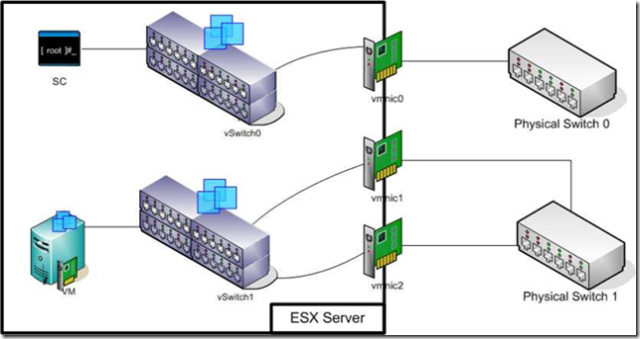
If vSwitch0 looses connectivity with Physical Switch 0 the ESX server is deemed to be isolated, despite their being no impact on VM availability. However if the connections to Physical Switch 1 fail the VMs are unavailable but no HA activity will occur. Clearly HA is not monitoring the right network.
So how about this one, VM network separated from SC network with different VLANs:
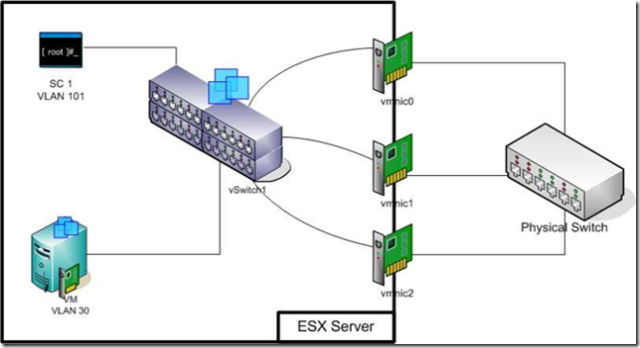
Here SC and VM traffic are both carried over the same physical links, so if SC has lost it’s physical links then so has the VM. However (that’s but with more letters) we’re now dependent upon the SC VLAN being up and I believe that Cisco trains network engineers to Shutdown a VLAN before making changes to it.
I have definitely heard of environments that used the above configuration and had every VM in their whole HA environment shutdown because the networks team were making VLAN changes.
The best solution I can find is to use a single vSwitch with VLANs to segregate traffic (and maybe NIC active/Standby set to guaranteed bandwidth) and at least two SC ports on different VLANs, like the diagram below:
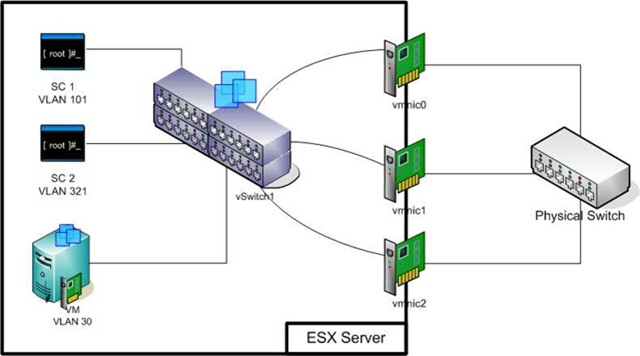
Here HA monitors the physical networks used by VMs but the risk around VLAN shutdown is reduced as two VLANs must be concurrently shutdown to cause an HA event.
Please suggest any alternate configurations
© 2007, Alastair. All rights reserved.

 RSS - Posts
RSS - Posts