
Getting Granite to operate in containers wasn’t a huge deal, as I covered in my last post. Containers are a packaging mechanism; I still need an orchestration platform to run these containers in production. Kubernetes is the de facto standard for container orchestration, so I deployed K3S and started writing some manifest files. K3S is a lightweight way to deploy a Kubernetes cluster using as little as a single virtual machine or a whole scale-out cluster. I use it in my home lab for experiments before committing to use more resources on public cloud platforms.

Building an application on a Kubernetes cluster is usually a layered process, starting with deployment infrastructure, then a persistence layer, and finally, the more transient execution layer. I like to wrap the whole process in a shell script, although I usually copy & paste lines from the script into a command prompt for testing.
The first manifest creates a namespace and deploys a container registry to hold my Granite container images. There are also config files to tell both the Docker runtime and K3S to use the new registry and not require a trusted certificate. Once the registry is available, I build the Granite container images and push them into the registry, ready for the following manifests to use.
The second manifest deploys the static resources: the database and web servers. Both use Kubernetes service definitions so that they can be recovered from failure. There is only one replica for the database server but multiple replicas for the web server with a load balancer. The registry, database, and web servers use container volumes for data persistence. On a single-host K3S deployment, I can use the local disk, but when this goes to a proper Kubernetes cluster, I’ll need to use shared storage visible to the entire cluster. K3S provides a native load balancer; I’ll need to integrate an external load balancer when I deploy on the public cloud. I again learned that I have been teaching good practices but not following them. My Python code has the database server name hard-coded, along with the username and password for accessing the database in plain text. I should pass the database name as an environment variable and store the credentials in a secrets manager—either a Kubernetes secret or an external secrets management tool like Hashicorp Vault. I had left these changes until the Kubernetes stage, as manifests are a convenient way to set environment variables, and most K8S clusters include CoreDNS to allow internal name resolutions between pods on the same cluster.
The final manifest is for the containers that run the automated tasks. I used the built-in Kubernetes jobs functionality for my first test, allowing K3S to start each container at regular intervals using cron syntax. The downside of the cron syntax is that the maximum frequency is once per minute, which is much slower than when my scheduler would launch tasks. For the first test, the Job definition is OK. I tuned the frequency for each task until the backlog of orders sorted itself out. For actual deployment, I will need a better scheduler. I need to learn to create a Kubernetes Operator: a container that manages resources on a Kubernetes cluster and will allow me to launch containers more frequently. Using an operator will also allow me to use a manifest to send configuration changes to the operator to set the frequency rather than using a database table as my scheduler does or to scale the number of concurrent tasks.
Despite the slow rate of containers, after leaving my K3S host running for a few weeks, Granite had processed thousands of orders and delivered a couple of million dollars of imaginary products.
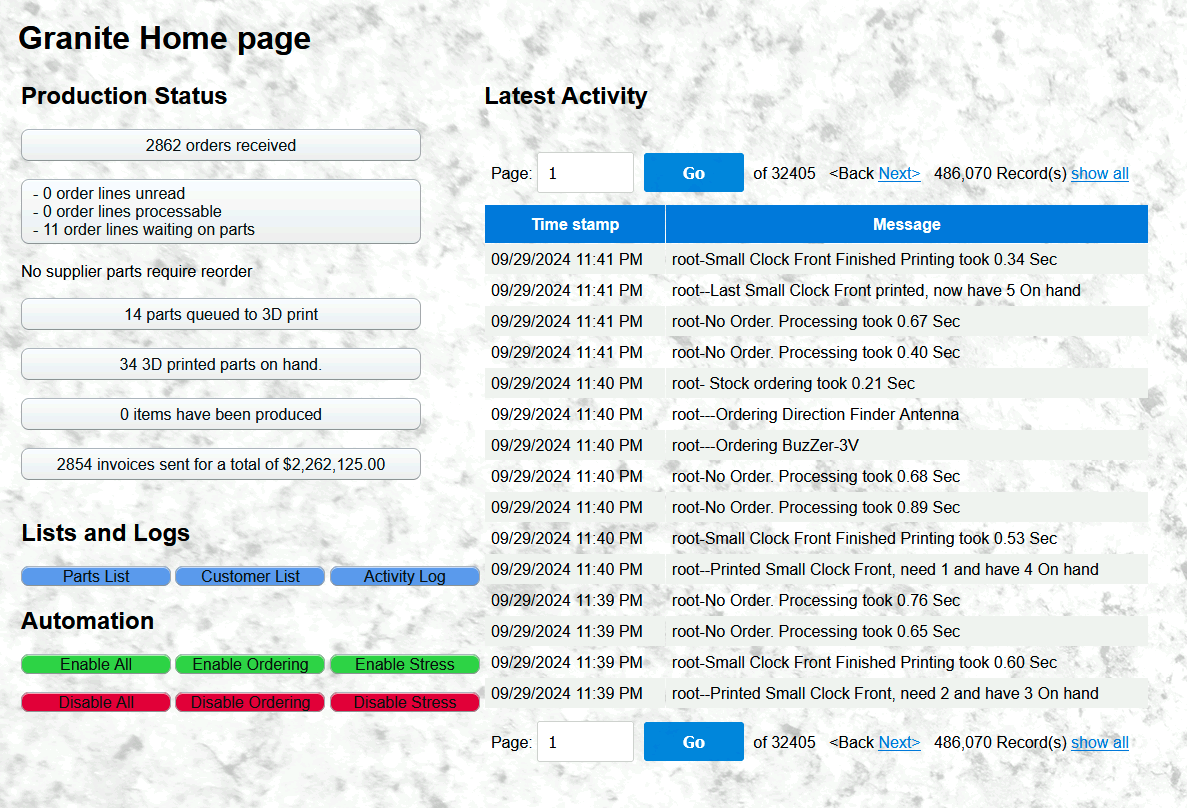
Before I am ready for Granite to run on a public cloud Kubernetes platform, there is more work to do. Moving an application from one platform to another requires revisiting design decisions, and there are plenty of best practices that pay off over time. This isn’t cutting-edge rocket science; it is simply work that must be done. I need to start paying down my accumulated technical debt from thinking short-term about earlier projects, specifically:
- Separate configuration from code
o Environment variables
o Secrets management - Use cluster-wide shared services
o Volumes for persistent data
o External load balancer
© 2024, Alastair. All rights reserved.

 RSS - Posts
RSS - Posts