
One of the first things that I saw in the Cohesity hardware is that it looks a lot like a hyperconverged infrastructure or scale-out software-defined storage. Multiple nodes in an enclosure, each with a mix of SSD and hard disk plus a reasonable amount of compute power. The nodes are clustered together to provide a distributed storage platform. Cohesity doesn’t seem to want to replace your SAN, but their storage is fast enough that you can run VMs from it for fast service recovery without waiting for data to copy in a restore. Once the VMs are running and service is restored, the VMs should be migrated back to your production datastores which Cohesity will do automatically. I made a short video showing this Cohesity Instant-Mass-Restore functionality in operation on my little lab. There is also a report from ESG that looks at the difference between bulk copy restores and Instant-Mass-Restore.

Disclosure: This post is part of my work with Cohesity.
Setup
To illustrate the instant-mass-restore function I created five disposable VMs, simple Windows Servers joined to my lab domain. I also created a protection job for these VMs that would take a full backup once per day and retain that backup for 30 days; this is the standard Bronze protection policy. The following day I checked that the protection was in place before “accidentally” deleting the five VMs from vSphere so that I can restore them to their original location.
Restore Process
The restore process starts with searching for the objects you want to restore. In my lab, I knew that all the VMs were named “Win-xx,” so I simply searched for “Win” and got both the list of VMs and the protection job that contained the VMs.

I could have used the “Show VM List” link on the IMRTest job, but I simply selected the five VMs from the list and moved on to the recovery options. I wanted to recover from the last backup, the default options for the VMs were correct. I also wanted them back where they came from and connected to the network so that they were back in operation as fast as possible, again great defaults settings. Notice that at the bottom I could have added more VMs to the restore before starting the operation, I simply clicked Finish.
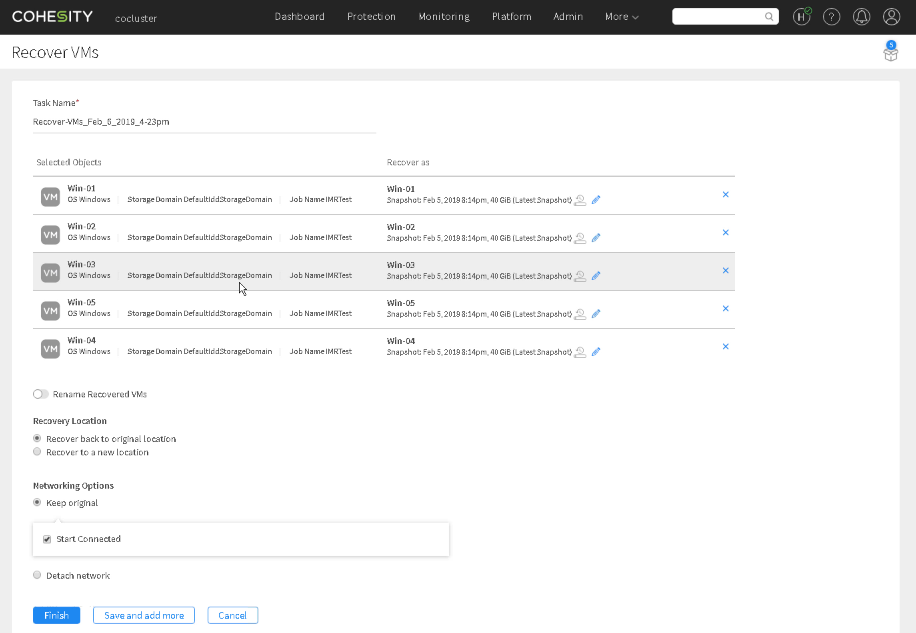
From clicking the “Recover” button to the recoveries being in progress took 30 seconds. From here on the tasks were all automated by the Cohesity cluster with no further action required from me.
On the vSphere side, the first action was a new NFS datastore presented to the host from the Cohesity cluster. Just like any other NFS datastore, VMs can be registered and run from this datastore. The datastore will only be here until the recovered VMs are migrated back to their original datastore.
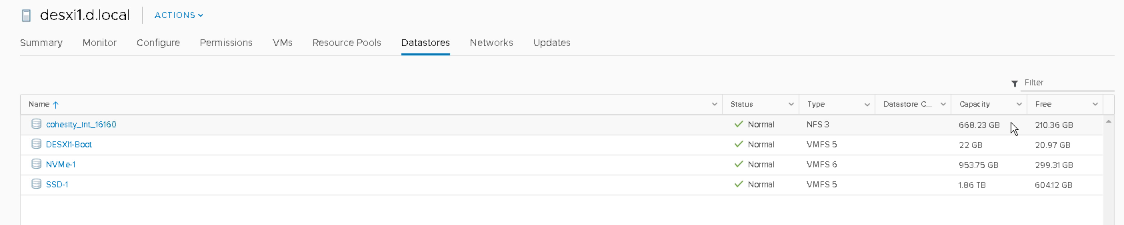
Next, the five VMs were registered with the ESXi server and immediately powered on and soon back to operation as they were at the backup time.

Once the power-on tasks completed, the VMs were relocated to their original datastore, by this point it was 90 seconds from me clicking the Recover button and, the five VMs were booting up.

The time required for the storage migrations depends on the size of the VMs and the performance of the Cohesity cluster, your network, and the destination datastore. In my lab, the Cohesity virtual edition is on the same datastore as the protected VMs, which has a single SATA SSD. Using a single SSD and a non-optimized SATA driver resulted in a very slow migration. A physical Cohesity cluster and a production-grade datastore will provide far better performance.
No Loss of Protection
Despite starting the VMs up from the Cohesity backup storage, there was no change to the backup stored snapshot, and I could restore from that snapshot again. Another great feature is that the protection job did not need to be reconfigured. The restore created a new VM, usually when you delete a VM and create a new one with the same name your backup software will need to be reconfigured to backup the new VM. Cohesity knew why the new VM was created and updated its own protection job. Another small way where Cohesity makes things simple.
Instant Mass Restore
Having your backups stored on a software-defined storage cluster allows application recovery without waiting for bulk data copies. The service is operational before the VMs are copied back to their original location. Recovery times are closer to the failover time for active/standby application clustering than to conventional recovery using backups.
© 2019, Alastair. All rights reserved.

 RSS - Posts
RSS - Posts